Does an AI Visibility Score Actually Mean Anything?
A fair objection is going around: a visibility score is not a booking, so why pay to watch a number rise while your rooms fill the same old way? I run these scores on hotels I built myself, so let me make the honest case for what they are worth — and concede, up front, what they are not.
A thermometer is not a fever either, and nobody throws out the thermometer. I half-agree with the critique, so let me reframe it around the question that actually settles things: can you connect something you do to something you measure? My answer, earned on hotels I built myself, is yes — a bit. And “a bit” is a great deal more than the “not at all” most hotel marketing quietly runs on.
Let’s grant the strong version first
The sharpest critique of AI visibility tooling is also the correct one, so I will say it plainly before defending anything. A visibility score is not revenue. More mentions in more answers is not the same as more rooms sold. A dashboard can glow green all year while a hotel fills exactly the way it always did, and if the only thing the tool ever sells you is the measuring, then yes — you are paying a subscription to watch a number.
I have built tools in this space and seen the vanity version up close, so I will not pretend to disagree with most of that. I am here to argue something narrower and more useful: the score is a leading indicator you can sometimes tie back to your own actions, and that partial link is worth more than the certainty nobody in this field actually has. The real question is not “is the score a booking?” — plainly it is not — but “can you connect what you do to what you measure?” The rest of this guide is my honest answer: a bit, and here is exactly how much.
What the number actually is
A visibility score, done properly, is not a single magic figure. It is a measured rate: across a fixed set of the questions guests ask in your market, how often does each engine name you, cite your own site, and in what company. Run that every week and you are watching one thing — whether the models that increasingly sit between a traveller and a booking page can currently retrieve and recommend you.
That is worth measuring for the same reason occupancy pace is worth measuring before the guests arrive: it is the early shape of demand. Nobody confuses pace with revenue, but nobody flies blind on it either. The score plays the same role one retrieval layer earlier.
None of those three is a sale. All three are observable, repeatable, and — this is the part the sceptics tend to skip — they move when you change your inputs. A number that responds to your actions is the definition of a lever, even if it is not the prize.
Is the number real, or am I scoring noise?
Here is the objection that would actually sink the whole enterprise: if AI answers are random, then any score built on them is a coin-flip dressed up as a chart, and optimising it is superstition. That would be fatal. It also happens to be testable, so I tested it.
In my rankings-consistency study — 4,000 repeated queries, 6,249 hotel mentions across eight cities — the same hotel held the top spot in 50.5% of identical reruns on average, and in the most constrained markets that climbed to 96.1%. A coin flip does not do that. The variance is real, but it is governed by the city, the supply, and how the question is phrased, which means it is a signal you can read rather than static you cannot.
And the pattern is not a hotel quirk. Run the same method on Amsterdam bike shops — a niche I have no stake in — and the cross-engine ordering holds: one shop appears in all five engines, others in two or three, every week. Across the wider landscape work (19,579 prompts, six models) each engine even has a stable sourcing personality — Grok leans almost entirely on TripAdvisor, Gemini on the big OTAs. If this were noise, none of those regularities would survive repetition. They do.
“But those are the software’s questions, not a guest’s”
The strongest methodological complaint is that nobody measuring AI visibility can watch real travellers talk to real assistants — those chats are private — so the tools generate prompts themselves and grade you against questions a machine wrote. The premise is true. The conclusion does not follow, and here is why.
No survey researcher gets to poll the entire population either; they sample it, carefully, and the sample is informative precisely because it is built to mirror the real distribution. A prompt panel is the same move. The questions are not invented from thin air — they are modelled on how the engines themselves decompose hotel intent. My anatomy of ChatGPT hotel search shows location queries trigger a real web search 98% of the time (against 8% for definitional ones) and then fan out into four or five sub-queries. Build the panel around that observed behaviour and you are sampling the intent space, not making it up.
There is a second guard against fooling yourself: phrase prompts as a guest’s need (“I’m a cyclist spending a week in Paris—where should I stay?”), never as your own amenity list read back to you. The how-to lives in the prompt-tracking guide; the point here is that a disciplined panel measures questions shaped like the ones guests ask, in the destinations you actually compete in.
That last clause answers the other common jab — that these tools were built for category-first software shopping and bolted onto hotels, which are searched geography-first. A hotel panel that is anchored to a place by construction (“best boutique hotel near Bastille”) is geography-first by construction. The tool inherits the flaw only if you build it lazily.
Can you connect an action to the number? A bit — and a bit is the honest ceiling
Strip the debate down and it is about attribution: if I change something on my side, does it show up anywhere I can see? With AI search you will not get a clean lab result, and anyone selling you one is selling. What you can get is disciplined evidence — and a stable, weekly, per-engine score is the instrument that makes that evidence possible at all, because you cannot detect a change against a number that is pure noise. The consistency result above is what earns you the right to even attempt this.
The method I run is interventional, and deliberately boring:
- 1Baseline before you touch anything
Track for two or three weeks first, so you know the natural week-to-week wobble. Movement only means something against a line you have already watched sit still.
- 2Change exactly one thing, and log the date
New structured page, schema fix, a review push, an llms.txt, a placement on a third-party site the engines trust. One lever at a time, timestamped — or you will never know which one moved the line.
- 3Watch the per-engine line, not the blend
Look at the engine you actually targeted. A site change that wins ChatGPT may do nothing on Gemini, because they ground on different sources; a blended score would average that real result into mush.
- 4Confirm downstream, in the same window
Did the ChatGPT-User hits in your server logs and the branded search in analytics move in the weeks after? Two independent signals agreeing is as close to proof as this gets.
- 5Claim timing, not cause
Report “I changed X on this date and the line moved over the next runs,” never “X caused the bookings.” Show the sequence and let it persuade. Overclaiming is exactly the sin the sceptics are right about.
Here is the underrated part, though: the score is the closest observable to your action. Bookings sit at the far end of a chain stuffed with confounds — price, season, a heatwave, the competitor down the road who just refurbished. The visibility score sits one step from the lever you pulled, on a weekly clock, split by engine. If you want any shot at attributing what you did, that is where you have it — and from there you triangulate forward to the money.
And the number ties forward to money
Linking your action to the score is half the job; the other half is the score linking forward to revenue. For AI visibility that onward chain is unusually short, and every link is observable rather than inferred:
A weekly mention-and-citation rate across the engines, per destination. It is the earliest thing that moves — it changes the week the model starts retrieving you, long before any of it shows up in your accounting.
When the score climbs, the ChatGPT-User, Claude-User and PerplexityBot hits in your raw access logs climb with it. This is the only place you see the model actually fetch your page — no sampling, no estimate.
Then the sessions arrive: direct AI referrals, plus a fatter bucket of people who asked an assistant, got your name, and typed it into Google. The demand was created by AI; your analytics file it under branded search.
And at the end, a booked room with a name attached. The guest arrives with the recommendation already made and the trust already lent — which is why this traffic tends to convert harder than a cold OTA click.
Each link is something I have watched in the data. When ChatGPT began embedding hotel links on 7 May 2026, AI referral sessions across a 17,000-hotel panel jumped 62% overnight and then doubled week over week (+102%) while organic crept up 7% — net-new traffic, not reshuffled, as the direct-traffic study lays out. And that AI referral even keeps human hours: it peaks on Sundays, exactly when people plan trips. Noise does not keep a calendar.
The strongest evidence I have: a hotel built on the score
Arguments about leading indicators get hand-wavy fast, so I ran the cleanest experiment I could think of. I built a hotel’s demand from nothing — Hotel Ranque, no OTA contracts, no ad budget — using AI visibility as the only acquisition channel, and watched whether moving the score moved the bookings. (The name is a pun on rank. I am not above that.)
The score moved first, in the order you would predict if it were a real signal: a first Perplexity appearance around week four on a long-tail query, consistent presence across ChatGPT, Gemini and Perplexity by week twelve, generic “best boutique hotel in Paris” placements past week twenty. The bookings followed the curve, not the other way around — two or three enquiries a week early on, then eight to twelve, then more than the rooms could hold, which is when I stopped the experiment.
Then the part that turns “visibility” back into “bookings.” The booking form asked one question — how did you hear about us? — and of 52 answers, 21 said AI search, against 27 for Google and four for everything else. A channel that did not exist when I started the experiment came within a whisker of Google, on a hotel that had no other way of being found.
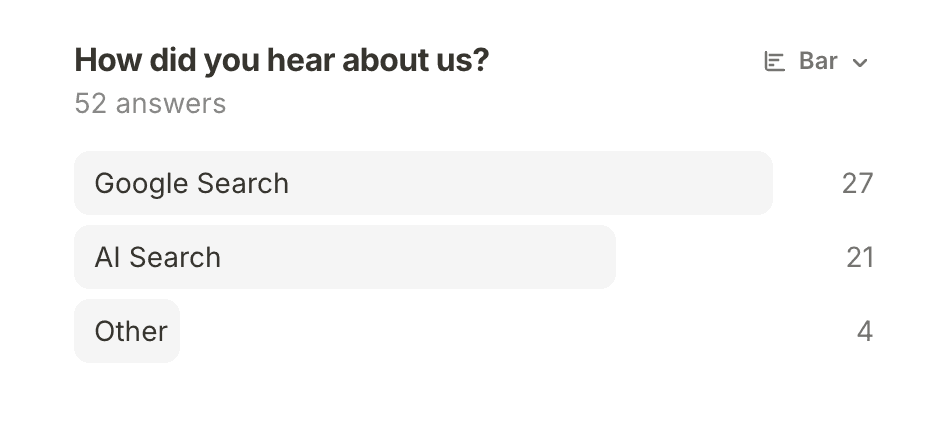
And that is the floor, not the ceiling. The “Google” bucket hides demand the assistants created — guests who asked ChatGPT, got the name, then typed it into Google to book. The hidden AI effect the attribution work keeps surfacing sits inside that 27.
One property is one data point, and I would not generalise a whole industry from it. But it is a clean one: where AI visibility was close to the only input, real bookings came out, the score predicted them, and the guests said so at check-in. You cannot get that result if the score is measuring nothing.
Telling a useful score from a vanity one
The critique lands hard on bad implementations, and it should. So here is the line I draw between a score worth paying attention to and a billboard for watching a number climb.
- Anchored to the destinations you actually sell in.
- Read alongside server logs and referral traffic, never alone.
- Repeated weekly so a change you made has somewhere to show up.
- Split by engine, because the levers differ per engine.
- Baselined before you act, so movement means something.
- One blended number with no link to traffic or revenue.
- Prompts reverse-engineered from your own amenity list.
- Category-first questions that ignore geography.
- Checked once a quarter, long after the movement is gone.
- “Make more content” as the only prescription.
Treat the score as a leading indicator and it earns its place: pull a lever, watch the line, then watch the logs and the branded search confirm it a few weeks later. Treat it as the destination and the sceptics are right about you. The metric is not useless; using it without the chain attached is.
FAQ
Further reading
This guide is the “why bother” case. For the mechanics of measuring without fooling yourself, the prompt-tracking guide is the companion; the numbers above come from my own research library.
AI Rankings Consistency Study
The evidence that AI hotel rankings are structured, not random — 50.5% to 96.1% top-spot stability.
How to Measure AI Hotel Traffic
The attribution gap, server logs as gold standard, and why analytics undercounts AI.
The ChatGPT Direct-Traffic Explosion
What happened to 17,000 hotels the day ChatGPT started embedding links: +62% overnight.
Hotel Ranque: built on AI visibility
The from-scratch experiment behind the 21-of-52 number.