AI Search for Bookstores in Tokyo (2026):Where AI search stops looking Western
TL;DR: Same playbook as the hotel and yoga studies — 22 prompts, EN and JA, US and JP proxies, every answer parsed and matched to 584 real bookstores — pointed at Tokyo. Three Tokyo-only findings emerge. Gemini almost never cites a store’s own website (just 5%) — instead it lives in a dense local-guide web (58% third-party guides like whenin.tokyo and Tokyo Weekender) that has no Western equivalent at the same density. ChatGPT cites .jp store domains 5× more in Japanese than in English — the sharpest language-to-TLD coupling in the whole study. And the top of the leaderboard is a clean duopoly: DAIKANYAMA T-SITE and Kinokuniya tie at a score of 122, with English-friendly stores and the Jimbocho used-book cluster filling the breadth tier below.
Executive Summary
Tokyo is where AI search stops looking Western.
The methodology is the same one we ran for Paris yoga studios and the AI hotel landscape — a fixed set of prompts, fired at every major AI engine, in two languages, from two countries, in a single week — except this time aimed at Tokyo bookstores, and with one structural caveat: Perplexity returned no usable data for this scrape, so only 4 engines carry the analysis (ChatGPT, Copilot, Gemini, Google AI Mode).
Three things are true of Tokyo and only of Tokyo in our studies so far:
- A dense local-guide citation web that Gemini lives in almost entirely. Just 5% of Gemini’s Tokyo citations are store websites; 58% are third-party guides (39% local editorial like whenin.tokyo and Tokyo Weekender + 19% expat media like GaijinPot and Japan-Guide). A Tokyo-specific taxonomy pass dropped the residual “other” bucket from 36% to 15% — the long tail wasn’t noise, it was a whole stratum of local guides that no Western city has at that density.
- The strongest language → TLD bias we have measured. On ChatGPT, .jp store domains are cited 5× more by Japanese prompts than English ones. Amsterdam was neutral at ~1.0×; Tokyo is the opposite extreme. Ask in Japanese and the engine leans hard into native .jp domains; ask in English and those same domains nearly vanish.
- A clean DAIKANYAMA T-SITE / Kinokuniya duopoly at the top. The Tsutaya design flagship and the national chain tie at 122 across all four engines. Below them, the breadth tier is dominated by English-friendly stores (Aoyama Book Center, Infinity Books) and the Jimbocho used-book cluster — exactly the stores Western editorial covers.
The core laws from the hotel and yoga studies survive intact (per-engine source strategies, platform-specific blindness, near-universal web-search triggering on ChatGPT at 99%). What’s new in Tokyo is which source strategy each engine picks, and how aggressively the language of the prompt steers which top-level domain gets cited.
Source mix by platform
For every cited URL we bucketed the source — the store’s own website, a social post, a local editorial outlet, an expat-media site, a global book-press outlet, a travel blog, a Google SERP, or other. A Tokyo-specific taxonomy pass resolved the long tail of local guides (whenin.tokyo, gltjp.com, Truly Tokyo, GaijinPot, Japan-Guide, visit-chiyoda) so the “other” bucket fell from 36% → 15% overall. The mix is wildly different per engine, and it maps to four fundamentally different ways of sourcing an answer.
Note: Perplexity is absent from this run — the scrape returned no usable Tokyo bookstore citations. All percentages and counts on this page are over the 4 engines that did return data.
Entity engine
89%Cites the store's own domain directly. Same lookup behavior we see for hotels in every market — Copilot is an entity-resolution machine. To win here, your store's own site has to be the canonical answer.
Self-referential engine
61%Cites google.com URLs back to itself 61% of the time — essentially re-presenting its own search results page. Real source diversity is low; ranking in ordinary Google results is the path in.
Social / editorial engine
21%Social (Reddit-led) is its single biggest bucket at 21%, with another 21% editorial_local and 13% book-press. Only 8% of ChatGPT's Tokyo citations are store websites. ChatGPT learns about Tokyo bookstores from communities and journalists.
Local-guide engine — the Tokyo signature
58%Gemini cites store websites just 5% of the time. Instead it runs on the local-guide web — 39% editorial_local + 19% expat_media = 58% third-party guides (whenin.tokyo, Tokyo Weekender, gltjp.com, GaijinPot, Japan-Guide). For Tokyo bookstores, Gemini is effectively a travel-guide aggregator, not an entity engine.
The Tokyo bookstore AI leaderboard
Aggregating each store’s surfacing across all 4 engines (chain locations merged), these are the most-cited Tokyo bookstores. Score is that cross-engine total — the times a store was named or cited across the four engines’ answers, summed and chain-merged. It is not a count of links to the store’s own domain: unlike Amsterdam bike shops, three of the four Tokyo engines surface stores mostly through third-party guides and communities, so a store can rank highly here while barely being cited at its own site (Gemini cites store websites just 5% of the time). Engines is how many of the 4 surfaced the store at all — the breadth signal. The top of the table is a tie: DAIKANYAMA T-SITE (the Tsutaya design flagship, surfaced by all 4 engines) and Kinokuniya (the national chain, surfaced by 3) both score 122.
The Tokyo bookstores AI recommends most — scored across ChatGPT, Copilot, Gemini and Google AI Mode combined (Perplexity returned no usable Tokyo data this run).
| Rank | Store | Score | Engines |
|---|---|---|---|
| #1 | DAIKANYAMA T-SITE | 122 | 4 / 4 |
| #2 | Kinokuniya | 122 | 3 / 4 |
| #3 | magmabooks | 59 | 2 / 4 |
| #4 | Kitazawa Bookstore | 57 | 2 / 4 |
| #5 | Aoyama Book Center | 55 | 4 / 4 |
| #6 | Infinity Books Japan | 47 | 4 / 4 |
Top cited sources, cross-platform
The buckets are one thing; the actual domains are another. These are the most-cited sources across all 4 engines — the Tokyo bookstore citation backbone. Two patterns stand out: Reddit (104 cites) and Tokyo Weekender (67) are the editorial anchors, and whenin.tokyo (47) is the single biggest pure local-guide site — exactly the kind of domain a naive taxonomy would dump into “other”.
| Engines | Cites | Bucket | Domain |
|---|---|---|---|
| 4 | 31 | store_website | aoyamabc.jp |
| 3 | 104 | social | reddit.com |
| 3 | 67 | book_press_global | tokyoweekender.com |
| 3 | 57 | store_website | store.kinokuniya.co.jp |
| 3 | 57 | store_website | store.tsite.jp |
| 3 | 47 | editorial_local | whenin.tokyo |
Language and TLD bias
Same intent, different language, different stores. On the same JP proxy, English and Japanese prompts returned mixed top-5 overlaps — some neighborhood queries fully converge, but genre and “iconic Tokyo bookstore” queries diverge sharply.
| Template | EN↔JA overlap (Jaccard) |
|---|---|
| dist_shimokita (Shimokitazawa) | 100% |
| dist_aoyama | 67% |
| late_night | 67% |
| dist_daikanyama | 50% |
| aesthetic | 50% |
| english_speaking | 43% |
The pattern is consistent: specific neighborhoods converge (Shimokitazawa is the same place in both languages, and the same stores get named), while generic “iconic Tokyo bookstore” queries split — English prompts surface tourist-famous and English-language stores, Japanese prompts surface a different local set entirely.
.jp vs .com is a language-affinity signal — the sharpest we’ve measured
| TLD | Store entities | EN cites | JA cites | JA/EN ratio | Reading |
|---|---|---|---|---|---|
| .jp | 8 | 3 | 15 | 5.00× | local-biased (sharp) |
| .com | 2 | 2 | 3 | 1.50× | local-biased (mild) |
On ChatGPT, .jp store domains are cited 5× more by Japanese prompts than English ones. This is the strongest language-to-TLD coupling we have measured anywhere — Amsterdam bike shops ran neutral at ~1.0×, Paris yoga’s comparable .com/.fr split was 0.59×. Ask ChatGPT in Japanese and it leans hard into native .jp domains; ask in English and those same domains nearly vanish from its citations.
The bias underneath the bias
The split above is query-driven — ask in Japanese, get .jp. But it sits on top of a structural tilt that runs the other way: the corpus these models train on, and the retrievers that rank sources at query time, both skew heavily toward English. That’s the most plausible reason the English-prompt path collapses onto tourist-famous and English-friendly stores — those are the entities best represented in the English-language web the engine leans on. The practical consequence for a Tokyo bookstore that wants the English-speaking traveller isn’t a machine-translated footer: it’s a genuinely useful English edition of your cornerstone pages, on crawlable URLs with proper hreflang, so you exist in both language substrates instead of only the .jp one.
Geography: ChatGPT respects wards
Tokyo geography is the test case where our usual accuracy metric stops being honest, so it’s worth reading the table carefully. When we asked ChatGPT for stores in a specific area, the results split along a structural line — ward-level prompts are accurate; neighborhood-level prompts look 0% only because of a labeling mismatch in the seed data.
| Prompt target | Type | In-target accuracy |
|---|---|---|
| Shibuya | ward | 100% |
| Shinjuku | ward | 79–92% |
| Jimbocho | neighborhood (in Chiyoda) | 0%* |
| Aoyama | neighborhood (in Minato) | 0%* |
| Daikanyama | neighborhood (in Shibuya) | 0%* |
| Shimokitazawa | neighborhood (in Setagaya) | 0%* |
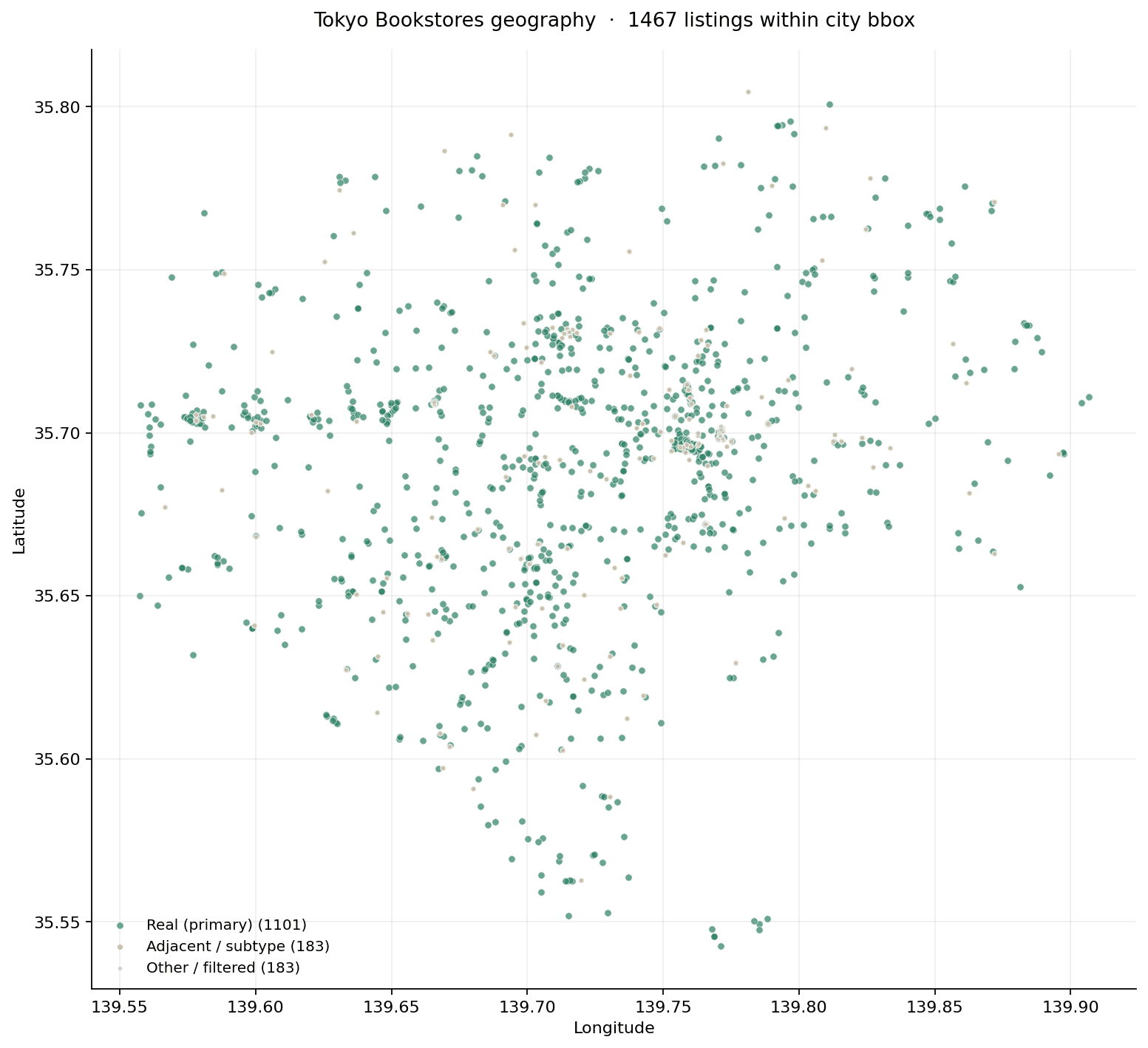
The 584 Tokyo bookstores on the map
The full reference set every answer was resolved against — 584 Tokyo bookstores with websites, covering the 23 Special Wards plus Musashino and Mitaka. Density follows Chiyoda (Jimbocho), Shinjuku and Shibuya — the historic used-book core and the two largest commercial wards.
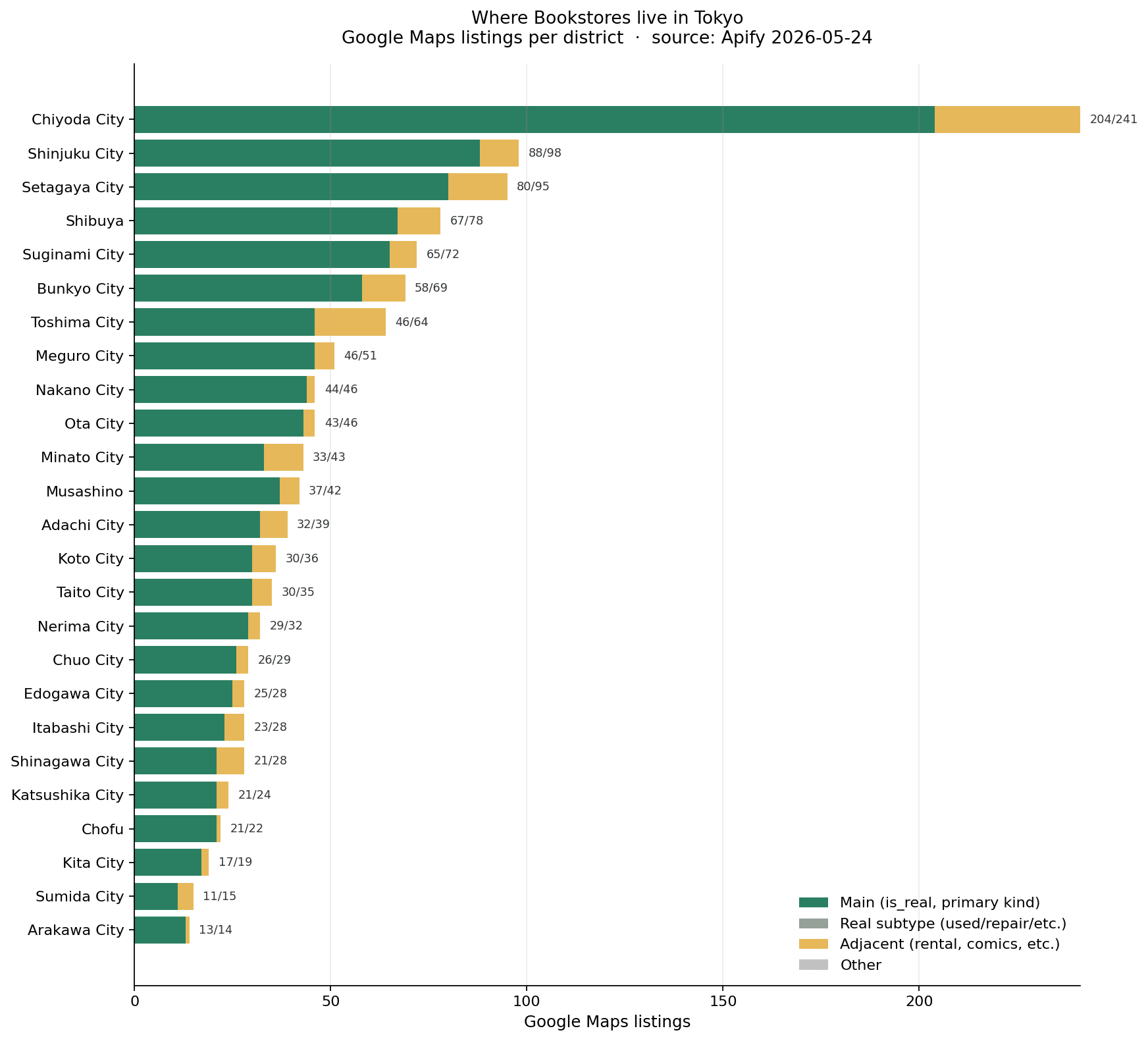
Stores per ward — the supply side
The same distribution, counted by ward. Chiyoda (the Jimbocho cluster) and the two big commercial wards lead; the outer wards are comparatively thin.
AI search behavior — and a data gap to flag
Two behavioural signals to report; one we measured cleanly, one we couldn’t.
Web-search trigger rate
ChatGPT triggered live web search on 95 of 96 captures — one prompt answered from training data alone. As with Paris yoga (96%) and our hotel studies, Tokyo bookstore queries are almost entirely search-driven, not pre-baked. The visible answer is grounded in live retrieval practically every time.
Fan-out queries — a genuine gap
Not captured for any Tokyo platform this run. AI Mode, Copilot and Gemini don’t expose the trigger / fan-out fields through our scraper, and Perplexity (which carried single reformulated queries for Amsterdam bike shops) returned no usable Tokyo data. Fan-out behaviour is a real data gap here — we lean on the ChatGPT trigger rate, the source-mix breakdown and the TLD findings instead, and flag the absence rather than papering over it.
Study design
Data collection
- 22 prompt templates × 2 languages (EN/JA) × 2 proxy countries (US/JP) × 4 AI engines
- Engines with usable data: ChatGPT, Copilot, Gemini, Google AI Mode. Perplexity returned no usable Tokyo bookstore citations in this run and is excluded everywhere on this page.
- Captured 2026-05-23 → 2026-05-24 via Bright Data
- 336 captures · 2,322 cited URLs · 858 distinct map entities
- For each answer we logged both the rendered text and every cited URL
What we measured
- Stores named per answer (chain-aggregated leaderboard + per-engine breadth)
- Cited URLs, bucketed into a Tokyo-specific source taxonomy
- Geographic accuracy vs the prompted ward (with the neighborhood caveat)
- EN/JA overlap per template; .jp vs .com citation balance by prompt language
- ChatGPT live-web-search trigger rate
The Tokyo bookstore reference set
We started from a 1,310-row Apify Google Maps seed covering Tokyo’s 23 Special Wards plus Musashino and Mitaka, filtered to book / used-book / rare / kids / magazine stores. Comic shops, hobby shops, stationery shops and thrift shops were flagged is_real = false and excluded; of the real bookstores that remained, 584 carry a verifiable website. Those 584 are the resolution registry an answer is matched against (by fuzzy name plus domain) — not a list we fed to the models. The one honest limitation of choosing the with-website subset: a real bookstore with no website can be named in an answer and still fall outside the registry, so the long tail of site-less shops is under-counted by construction.
How we turned answers into stores: the NER pipeline
AI answers are free text — “You could try Kinokuniya in Shinjuku, or the Jimbocho used-book cluster…” — not a clean list of businesses. To count anything, we first had to extract the store mentions. We ran each answer (and each citation’s anchor text) through a named-entity-recognition (NER) pass that works in four steps:
- Span detection. A transformer NER model tags candidate spans — business names and the location phrases attached to them (ward names, neighborhood names, station names, street addresses). A Tokyo-specific gazetteer (“Kinokuniya,” “Tsutaya,” “Daikanyama,” “Jimbocho,” “shoten,” “書店”) boosts recall on names the base model would otherwise miss, including kanji-script store names.
- Normalisation. Each candidate is lower-cased, romanised where the script differs, and stripped of boilerplate — “Tokyo,” ward suffixes (“-ku,” “City”), “Co. Ltd.,” trademark glyphs and punctuation — so “Kinokuniya Bookstore Shinjuku Main Store” and “紀伊國屋書店” collapse toward the same key.
- Entity resolution. Normalised mentions are matched to the 584-store registry using fuzzy string similarity plus a domain match when the answer cited the store’s own website. A mention only counts if it resolves above a confidence threshold; ambiguous or sub-threshold spans are dropped rather than guessed.
- Chain aggregation. Resolved entities that belong to the same brand (Kinokuniya, Tsutaya, Book 1st…) are merged so a multi-location chain isn’t double-counted, while the per-location coordinates are retained for the maps.
The 584 stores are the universe an answer can resolve to; it is not a list we showed the models. Everything in the leaderboard is a store an engine surfaced on its own and that the NER pipeline could confidently identify.
Caveats
- Perplexity excluded. The Bright Data Perplexity scrape returned no usable Tokyo bookstore citations in this run. Every chart, table and percentage on this page is over the four engines that did return data. We do not extrapolate or impute Perplexity numbers.
- Fan-out queries not captured. AI Mode, Copilot and Gemini don’t expose query trigger / fan-out fields through the scraper. The Amsterdam dataset carried Perplexity-side fan-out; the Tokyo dataset has none. We flag this as a genuine data gap.
- Neighborhood-vs-ward labeling. The seed indexes stores by official ward, so neighborhood-prompt accuracy (Jimbocho, Aoyama, Daikanyama, Shimokitazawa) reads as 0% even when results are correct. Ward prompts (Shibuya, Shinjuku) are the honest accuracy figures.
- Source taxonomy is approximate. The Tokyo taxonomy pass moved roughly 21 percentage points out of “other” into editorial_local / expat_media; ~15% of cites remain in the residual bucket (long-tail Tokyo blogs, niche review sites).
- Google AI Mode’s heavy reliance on google.com URLs (61% of its citations) may inflate its citation count relative to other engines.
- No author affiliation. The author has no commercial relationship with any of the stores in this study.
Tokyo is the third point on a spectrum
Run the same prompts at the same engines in three different cities and the engines keep their personalities, but the web underneath each vertical changes — and that, not the engine, decides where answers come from. The series now reads as a spectrum of who owns the citation layer:
- Amsterdam bike shops — the businesses own the web. Answers resolve to the shops’ own domains (Copilot 97%), and the top tier wins on every engine.
- Marseille coffee — the social/editorial web owns it. Engines lean on Reddit, Instagram and local blogs more than on café sites.
- Tokyo bookstores — a third layer owns it: a dense, Tokyo-specific local-guide web (whenin.tokyo, Tokyo Weekender, GaijinPot, Japan-Guide) with no Western equivalent at the same density. Gemini lives in it almost entirely (58% third-party guides, 5% store sites).
On top of that sits the finding unique to Tokyo: the sharpest language-to-TLD coupling in the whole series. Ask ChatGPT in Japanese and .jp store domains are cited 5× more than in English; Amsterdam ran neutral at ~1.0× and Paris yoga’s .com/.fr split was 0.59×. Tokyo is the point where the prompt’s language, not just the city, reroutes which businesses an answer can even see.
Frequently Asked Questions
Summarize with AI
Continue Reading
More on how AI search surfaces local businesses.