Starting with the simplest capture
Across April 2026 we logged the streaming event protocol of several Claude conversations. The simplest one we ran was:
Claude emitted seven content blocks: a brief text, a short thinking trace, a tool call to places_search, a longer thinking trace ranking the candidates, a tool call to places_map_display_v0, and a final text reply. We saw the full prompt, the tool inputs, the tool outputs, and the model’s internal reasoning. We’ll walk through this capture first, then look at what changed across the other prompts further down.
The pipeline (3 steps)
One call to Google Places
Claude rewrites the user’s natural query into a Google Places query and calls a single tool:
The response is 8 hotels with: name, address, latitude/longitude, rating, rating_count, place_id (Google CID), weekday_hours, price_level (mostly null), 5 sample reviews verbatim, and phone_number. No bookable inventory. No live availability. No price.
Filter 8 → 5, by rating + review volume + variety
Claude’s thinking trace is explicit about what it ranks on:
ALEX Hôtel & Spa stands out with its 4.5-star rating and substantial review count, plus the added appeal of its spa facilities and proximity to the train station, while Hôtel 96 edges ahead with the highest rating at 4.8 stars and a desirable location near the Calanques… I’ll select around 5–6 of these top performers to showcase with personalized insights.
No model-side ranking signal beyond what Google already gave it. Claude is re-ranking on rating, rating_count, and what it calls “variety of personality” (different neighbourhoods, different traveller profiles). The 8 candidates from Google become 5 picks.
Render a map with notes
Claude passes the 5 selected hotels — place_id, lat/lon, name, plus a one-line notes field per hotel — to a map widget. The widget enriches them with photos, website URL, and a Google Maps deep link. The user sees a map with five pins and a side panel.
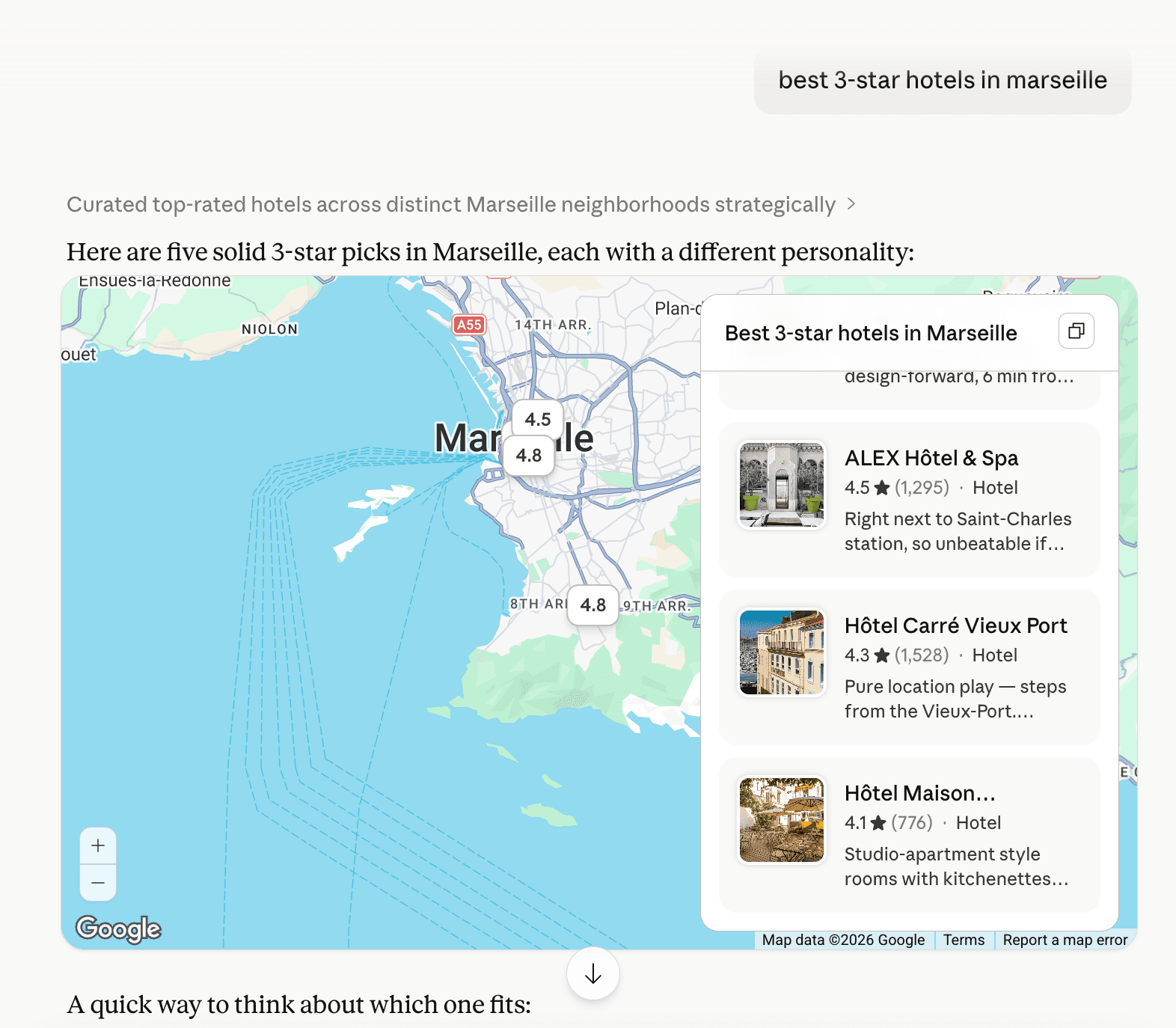
The rendered map widget. Three pins visible (4.5★ ALEX, 4.3★ Carré, 4.1★ Maison Montgrand) with the title Claude generated: “3-star hotels in Marseille.”
What this pipeline tells us
Single provider: Google Places
No Yelp, no TripAdvisor, no entity linker, no rank fusion. The place_id format is Google CID; types is the Google Places taxonomy. ChatGPT’s pipeline (see the anatomy article) blends 5+ providers; Claude is using one.
Ranking signal = Google rating × review count
Claude’s thinking explicitly cites high-star + high-volume as the filter. So for the foreseeable future, “winning” in Claude hotel answers means winning on Google Maps. Same playbook hotels already had — just amplified by an extra surface.
Reviews are surfaced verbatim
The tool returns 5 sample reviews per hotel (real Google reviews, full text). They shape Claude’s commentary — the line about “rooms are small but clean” for Hôtel Amoi maps directly to a review snippet. Bad reviews in the sample set propagate into the recommendation.
No live pricing, no booking — in default mode
The Places response had price_level: null on every hotel. Claude has an Apps surface (Booking.com, Tripadvisor, Trivago and a few others), but it’s gated behind the Connector Discovery setting, which ships off. With the toggle off, the booking step always happens elsewhere. With the toggle on, Claude curates a small connector picker — covered in the Turn connectors on section further down.
Memory personalisation is real
Persisted user context (“Nicolas’s expertise in hospitality”) visibly altered the response style — Claude framed the answer as professional shorthand, not tourist copy. Same model, different output for different users with different memories. Worth knowing if you benchmark Claude across accounts.
Other captures, same pipeline
Beyond Marseille we ran several more captures with different prompt shapes — budget tiers, dates, a French prompt, brand filters — to see how the pipeline reacted. Same conversation-log technique. Here’s what we asked and what Claude reached for first:
| # | Prompt (paraphrased) | First tool | Calls |
|---|---|---|---|
| 1 | best 3-star hotels in Marseille | places_search | 1 |
| 2 | budget hotels in Boston (~$200/night) | places_search | 3 parallel |
| 3 | dog-friendly boutique hotel in Barcelona | places_search | 3 parallel |
| 4 | design hotels in Reykjavík with sauna | places_search | 3 parallel |
| 5 | un hôtel boutique à Bordeaux mais pas Saint Pierre (asked in French) | places_search | 3 + 2 (two rounds) |
| 6 | 4-star hotels near Shibuya, May 15–18 | places_search | 1 |
| 7 | Marriott or Hilton in Lisbon for a business trip | web_search | 2 sequential |
| 8 | Marriott or Hilton near Shibuya, May 15–18 | places_search | 2 + 2 (two rounds) |
| 9 | Marriott in Reykjavík | places_search | 1 |
What each capture looked like
#2 Boston — budget hotels
“budget hotels in Boston, around $200 per night”
Three parallel places_search calls, sharded by price tier. Every hotel in the Places response had price_level: null. Claude’s reply still gave specific $150–$250-range estimates; the thinking trace flagged these as “approximate price ranges based on typical patterns” rather than tool data.
#3 Barcelona — dog-friendly boutique
“dog-friendly boutique hotel in Barcelona for next week”
Places has no pet-friendly attribute. Claude inferred dog policy from review text — “Dog friendly for a €15 fee” from a Villa Emilia review made it verbatim into the answer.
#4 Reykjavík — design hotels with sauna
“design hotels in Reykjavík with sauna”
The reply opened by disambiguating the Marriott-affiliated Design Hotels™ brand from design-forward boutiques generally. Brand recognition came from review text — an ION City review explicitly says “Member of Design Hotels™” in a guest write-up.
#5 Bordeaux — French prompt, “not Saint Pierre”
“un hôtel boutique à Bordeaux mais pas Saint Pierre”
Asked in French, searched in English, replied in French (map title too). Le Boutique Hôtel and Hôtel de Tourny were returned by Places but dropped from the answer for being too close to Saint Pierre. Yndo and La Course were pulled from training and verified via the second-round search.
#6 Tokyo — 4-star hotels near Shibuya, May 15–18
“4-star hotels near Shibuya in Tokyo, May 15–18”
One query was enough — Claude didn’t shard. Places returned hotels in both Shibuya and Shinjuku; the Shinjuku ones were dropped at synthesis time. Star-tier verification came from review text: a Granbell review saying “this is a 3-star hotel, not a 4” pushed it down the ranking. Places has no star field. The dates appeared in the map title and the closing “want me to check rates?” offer; the search call had no date parameter.
#7 Lisbon — Marriott or Hilton, business trip
“a hotel in Lisbon for a business trip, Marriott or Hilton”
The only capture that didn’t touch Places. The reply quoted “17,000 square feet of flexible event space” pulled from marriott.com directly, with an inline citation to that page. No map. None of the other captures surfaced citations.
#8 Tokyo — Marriott or Hilton near Shibuya
“Marriott or Hilton near Shibuya, May 15–18”
Same prompt structure as Lisbon (chain-or-chain) but with a specific neighbourhood anchor — this time Claude stayed in Places. Places has no chain-affiliation field; non-chain hotels that came back (Cerulean Tower, Shibuya Excel Tokyu) were dropped using Claude’s own brand knowledge. The map included a non-hotel Shibuya Crossing pin as a reference point.
#9 Reykjavík — Marriott
“a Marriott in Reykjavík”
Two results came back. The Reykjavik EDITION was identified as Marriott’s flagship (EDITION is recognised from training as a Marriott sub-brand; Places didn’t label it as such). ION Adventure was identified as a Bonvoy partner via Design Hotels — partly from a review quoting “my Marriott Bonvoy Platinum status, which is honored at this hotel”. The map showed only the EDITION; the prose mentioned both with caveats.
A couple of thoughts, not conclusions. Most of the variation across these captures sat around the Places call — how it got sharded into parallel queries, what got pruned at synthesis time, what got filled in from review text or training when Places didn’t carry the attribute. The Places call itself stayed steady.
Turn connectors on, and the pipeline branches
Everything above describes Claude with connector discovery off— the default. Connector discovery is a setting (Settings → Connectors → Discovery) that lets Claude proactively suggest external apps it could call. None of our nine captures invoked one because the toggle was off. So we tried something else: we asked Claude to book a hotel, and watched what happened.
Step 1 — Default mode: Claude offers to turn discovery on
Asked “Can you book me a hotel in Paris?” with discovery off, Claude doesn’t book and doesn’t go silent. It surfaces an inline opt-in prompt: “Turn on connector discovery — Claude will help you find available connectors in your directory.” Decline and it falls back to gathering travel preferences (when, who, what) for a Places-style search.
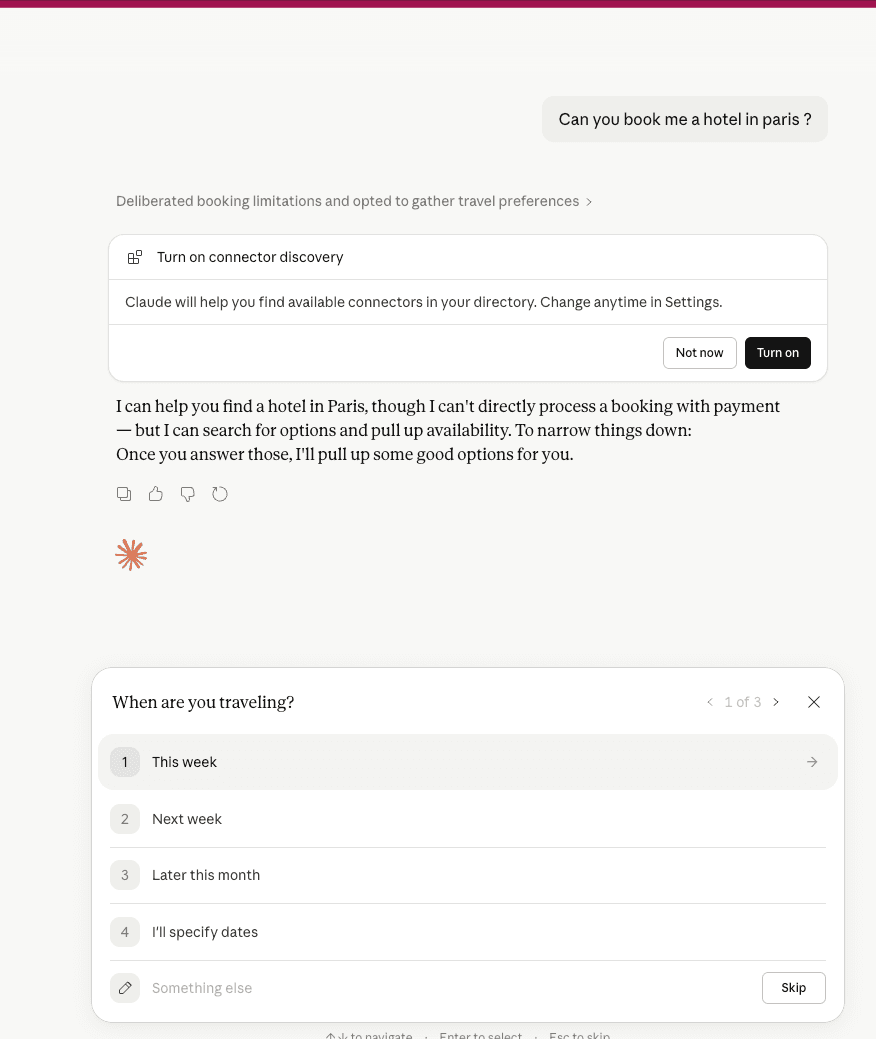
Default behaviour. Booking request → opt-in prompt for connector discovery, then fallback to a preference-gathering chat (“When are you traveling?”).
Step 2 — The setting itself: off by default
In Settings → Connectors there’s a Discovery toggle: “Let Claude surface connectors from the directory that may be relevant to your conversation.” It ships off. Connectors the user has already configured (GitHub, Attio, Gmail, etc.) stay configured per-tool, but Discovery is the gate for proactive surfacing.
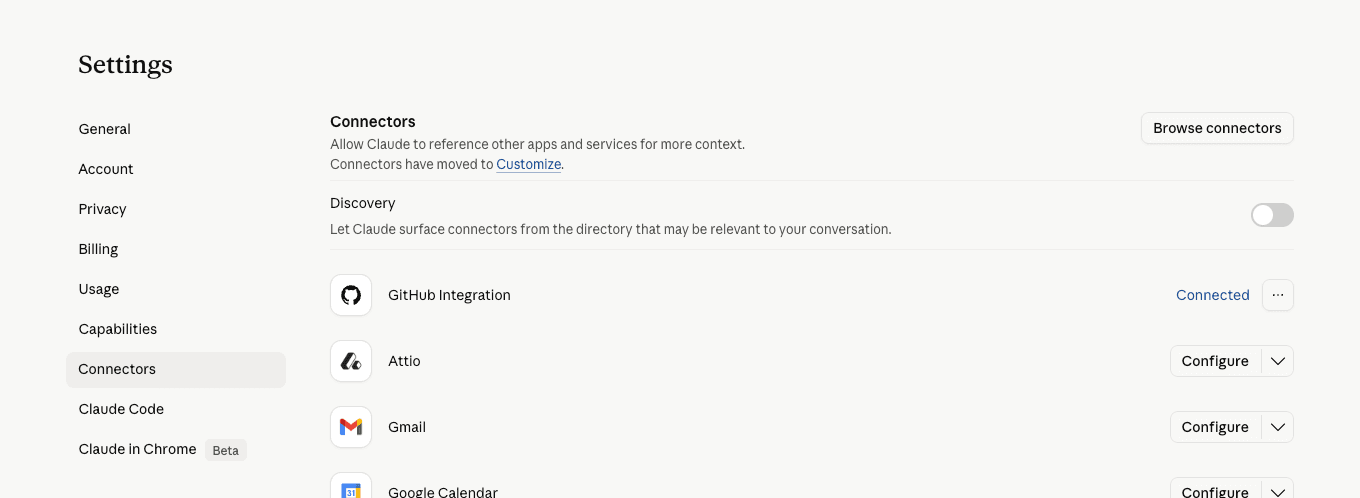
The Discovery toggle ships off. This is the reason all nine of our earlier captures hit Google Places — not a property of Claude’s pipeline, a property of the default permission state.
Step 3 — With Discovery on: Claude curates a connector list
Flip the toggle, ask the same booking question, and Claude returns a panel titled “Connectors that could help — A few good options for finding cheap central Paris hotels for this week.” The list this week is a small curated set headed by Booking.com, Tripadvisor, and Trivago, plus a Browse all connectors escape hatch. Each shows a one-line value prop and a Connect button (Trivago is greyed because the user had disabled it for this chat).
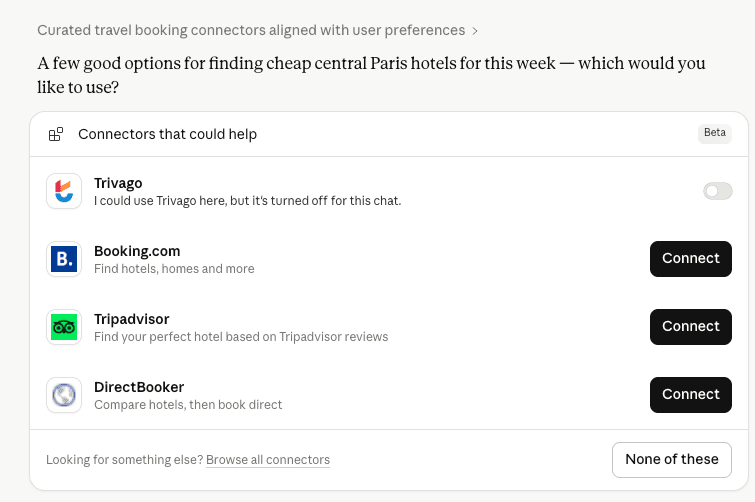
The connector picker. A small curated set of OTAs plus a Browse-all escape. Claude positions itself as the curator, not the booking engine — the user still has to Connect each one explicitly.
The actual finding
The Places-only behaviour we documented isn’t how Claude searches hotels — it’s how Claude searches hotels in default mode. The pipeline has a second branch that fires when the user turns on connector discovery, and on that branch Claude becomes a curator picking which OTAs to surface. Right now the curator shows three or four names. That’s the actual product.
The future of apps and connectors
Today, the curated list shows three or four OTAs. That works at this scale. But Claude has been explicit it won’t run sponsored ads, so when the supply of connectors grows — and it will — the question becomes: how does Claude pick which three or four to show? Without an auction, the curation logic itself is the product.
- No ads means no auction. So what’s the signal?Anthropic has said it won’t sell placement. So when there are 30+ travel connectors competing for the slot, something else has to decide. User history (which OTAs has the user logged into elsewhere?), geography (Booking.com leans EU, Expedia leans US), query specificity (luxury vs budget vs alternative-stays), or Anthropic-side partnership tiers. Probably some mix. None of it is public yet, and the choice will shape who actually gets in front of the user.
- Chains are next.Marriott Bonvoy, Hilton Honors, IHG One Rewards, Accor ALL — every loyalty programme is a candidate connector. Once one ships, the others have to follow. That’s a parallel layer of supply: brand connectors that route the user straight into the chain’s own booking flow, bypassing the OTAs entirely.
- Direct-booking platforms are next-next.Direct-booking platforms like The Hotels Network are the natural next entrant — a connector that surfaces “book direct on the hotel website” as an option, bypassing both OTAs and chain loyalty flows. That makes the field three layers deep: OTAs, chain loyalty programmes, and independent direct-booking platforms. All competing for the same three or four visible slots.
- The OTAs still missing today.Expedia, Hotels.com, Airbnb, Agoda, Kayak — none in this week’s curated set. Either they don’t have a Claude connector live yet, or the curation logic preferred others. Once they’re all in the directory, the visible-list problem gets harder.
- The default list is the product. Browse-all is the long-tail fate.Whatever Claude shows in the default panel determines who gets the click. There’s a Browse all connectors escape, but realistically that’s where everyone who isn’t in the default three or four ends up. So the optimisation game stops being “buy placement” (impossible — no ads) and starts being “ship a connector that earns selection” — quality, latency, completeness of data, brand recognition with the user. No marketplace mechanic yet. It’s closer to App Store editorial than to Google Ads.
How this differs from ChatGPT
ChatGPT’s hotel pipeline is a 12-system, 5-provider stack with entity linking, RRF fusion, and a Yelp/TripAdvisor blend. Claude’s, today, is a single Google Places call followed by an LLM-side re-rank. Different optimisation surfaces:
| Dimension | Claude (Apr 2026) | ChatGPT (Apr 2026) |
|---|---|---|
| Data providers | 1 (Google Places) | 5+ (Google, Yelp, TripAdvisor, etc.) |
| Ranking signal | Google rating + review count | RRF fusion + entity linking |
| Reviews surfaced | Verbatim, 5 per hotel | Synthesised across providers |
| Live pricing | In connectors (Discovery off by default) | In Apps / Ads |
| Booking integration | Curated connector picker (Booking.com / Tripadvisor / Trivago and others), gated behind Discovery toggle — no ads, selection logic not public | ChatGPT Apps |
| Sponsored ads | None — Anthropic has stated they won’t run ads | Yes (since March 2026) |
| Map render | Yes (Google embed) | Yes |
| Memory personalisation | Yes, observed | Yes |
Implication for hotels
For Claude visibility in default mode, Google Maps presence is the lever — rating, review count, complete profile, photos, accurate name and address. The Apps surface (Booking.com, Tripadvisor, Trivago and a few others) only fires when the user turns on Connector Discovery, and there it’s a small curated list rather than an open auction. Anthropic has been explicit it won’t run sponsored ads, so the equivalent of ChatGPT’s ad slots isn’t expected to appear — the optimisation game is “be one of the curated connectors” rather than “buy placement.”
Caveats and open questions
A handful of prompts from one Claude account, captured at the end of April 2026. Things worth keeping in mind:
- Small sample. We were watching how the pipeline reacts to different prompt shapes, not estimating frequencies.
- Single account with persistent memory. Claude’s thinking traces repeatedly referenced the user’s hospitality background; a fresh account would likely look different.
- The original captures had Connector Discovery off, which is the default. We followed up by enabling it and capturing the connector picker (see the connectors-on section). That captured the second branch of the pipeline; we still haven’t observed what happens after the user clicks Connect on, say, Booking.com — that’s the next test.
- Tool routing is moving. Lisbon used
web_search; Tokyo+chains stayed on Places. The trigger between the two isn’t obvious from this small set.